本演習では、気象観測データを用いて簡単な統計解析と結果の描画の実習を行う。 前半(1、2章)では一次元時系列データ(気象庁AMeDASデータ)を、後半(3章)では四次元データ(NCEP/NCAR大気再解析データ)を用いる。 解析にはPythonを用いる。フリーで気軽に導入できること、各種データ解析用のライブラリが充実していることなどから最近各分野で急速に普及しており、地球科学分野においても例外ではない。
本HPでは気象データの解析を題材に話を進めるが、Pythonの基礎については以下のサイトに非常に良く まとめられているので是非参考にされたい:
また、気象データの描画方法については以下に詳しい:
既に述べたように、Pythonにはデータ処理・解析の目的に応じて多種多様なライブラリが用意されている。 この章では、以下のライブラリを使って簡単な描画と統計解析を実践してみる(他にも色々とあるので 興味がある人は自分で調べてみてください)。
Matplotlib: 可視化に用いる最も一般的なライブラリ。他の可視化ライブラリも内部ではこれを呼び出していることが多い。[リンク]
SciPy: 科学計算ライブラリ。線形代数、数値積分、統計検定などのルーチンがある。[リンク]
ただし、これらはPythonでの最も基本的な解析ツールであり、他にも目的に応じて様々なライブラリが提供されている。 解析・描画には幾通りもやり方があるので、興味がある人は各自で調べて色々と試してみてほしい。
時系列データ(1次元)の解析として、表形式のデータである気象庁アメダスデータ(data/AMeDAS/Kyoto/Kyoto_***.csv)を用いる(データは気象庁HP (過去の気象データ検索)から取得した)。
なお、生の観測データには欠損値や異常値が含まれることがしばしばある。これらの処理については(1980年以降のAMeDASデータを扱う分には必要ないはずだが)別途こちら(A.データの品質管理)にまとめたので興味があれば参照されたい。
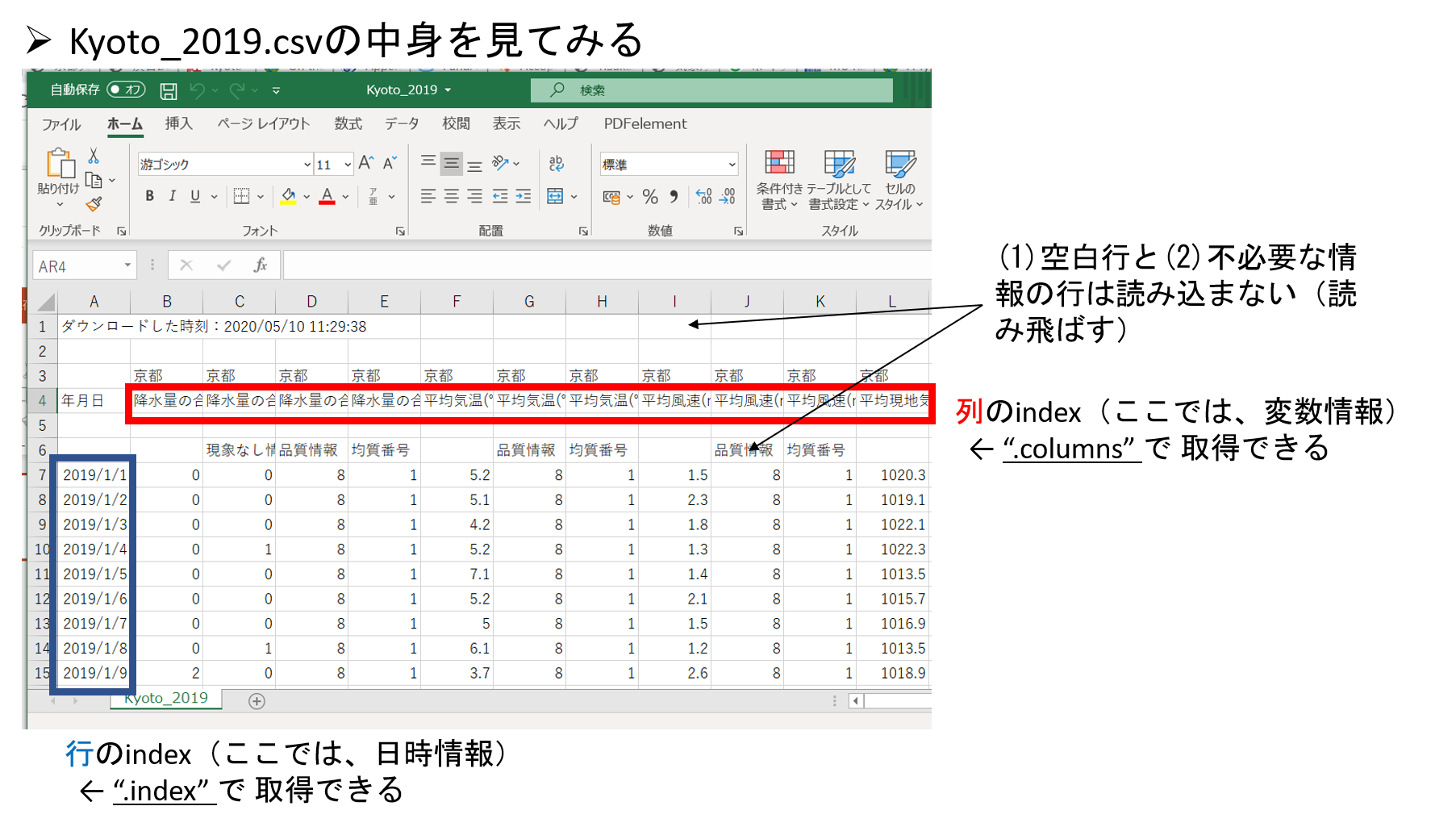
Excelで見慣れていることと思うが、csvデータは行にも列にもインデックス(ラベル)を持った二次元のデータである(下図を参照;この例では、行のインデックスが日付、列のインデックスが観測変数)。このようなデータ構造をpandasではDataFrameという。これに対して、列or行の一方のみインデックスを持つ一次元のデータ構造をSeriesという。
Linux端末では、Excelの代用としてLibreOfficeが使えるのでファイルを開いて眺めてみると良い。 コマンド例:
$libreoffice (ファイル名)
pandasでデータを読み込むと、一つ一つのデータにインデックスが「タグ付け」される。以下に示すように、これらインデックスの値・範囲を指定することによって、データの一部を適宜切り出して描画・解析に用いることができる。
また、時系列データを解析しやすいように時間方向のインデックスをDateTime型(日時・時刻形式)として読み込んでおくと便利である。こうすることで、後に示すように月や曜日を指定してデータを抜き出すことが可能となる(これはデータ解析で大きな利点である!)。
import numpy as np # ここで必要なライブラリを読み込む
%matplotlib inline
import matplotlib.pyplot as plt
import pandas as pd
import datetime
from scipy.optimize import curve_fit
yst = 1960; yen = 2023
dlist = []
for yy in range(yst,yen+1,1): # range(start,stop,step)は "start"から"stop"(ただし,stopは含まない)まで増分"step"の等差数列を作る
cyr = str(yy) # 文字列化
file = "../../DB_2020/data/Kyoto/Kyoto_" + cyr +".csv" #<---【注】"data/AMeDAS/Kyoto/Kyoto_"にパスを変更のこと
df = pd.read_csv(file,encoding = "shift-jis",header=2,index_col=0,parse_dates=[0])
# "encoding=":文字コードを指定、"header=2":2行目をヘッダー行(変数情報)に指定、"index_col=0": 0列目をインデックス行(時刻)に指定
# ""parse_dates =[0]": 「日時」の型として読み込む(これにより、年・月・曜日といった情報を簡単に取り出せる)
df = df.iloc[2:,:] # ヘッダーの余計な部分(空白行など)を除いて上書き
# これで一年分のデータのかたまりができた
dlist.append(df) # listに要素(df)を追加していくことで
# pandas.concatで、データのかたまり(41年分)を結合する
dfm = pd.concat(dlist,axis=0) # axis=0 (時間軸方向)に結合
dfm.head() # 最初の5行分を表示
| 降水量の合計(mm) | 降水量の合計(mm).1 | 降水量の合計(mm).2 | 降水量の合計(mm).3 | 平均気温(℃) | 平均気温(℃).1 | 平均気温(℃).2 | 平均風速(m/s) | 平均風速(m/s).1 | 平均風速(m/s).2 | ... | 平均湿度(%) | 平均湿度(%).1 | 平均湿度(%).2 | 日照時間(時間) | 日照時間(時間).1 | 日照時間(時間).2 | 日照時間(時間).3 | 最多風向(16方位) | 最多風向(16方位).1 | 最多風向(16方位).2 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 年月日 | |||||||||||||||||||||
| 1960-01-01 | 0.0 | 1 | 8 | 1 | 8.9 | 8 | 1 | 2.9 | 8 | 1 | ... | NaN | 0 | 1 | NaN | NaN | 0 | 1 | NaN | 0 | 1 |
| 1960-01-02 | 0.0 | 1 | 8 | 1 | 5.7 | 8 | 1 | 2.2 | 8 | 1 | ... | NaN | 0 | 1 | NaN | NaN | 0 | 1 | NaN | 0 | 1 |
| 1960-01-03 | 0.0 | 1 | 8 | 1 | 4.1 | 8 | 1 | 1.5 | 8 | 1 | ... | NaN | 0 | 1 | NaN | NaN | 0 | 1 | NaN | 0 | 1 |
| 1960-01-04 | 0.0 | 1 | 8 | 1 | 8.0 | 8 | 1 | 1.7 | 8 | 1 | ... | NaN | 0 | 1 | NaN | NaN | 0 | 1 | NaN | 0 | 1 |
| 1960-01-05 | 0.0 | 0 | 8 | 1 | 7.9 | 8 | 1 | 2.8 | 8 | 1 | ... | NaN | 0 | 1 | NaN | NaN | 0 | 1 | NaN | 0 | 1 |
5 rows × 39 columns
◯ [関数] pandas.read_csv (csvファイルの読み込み)¶
ここでは、pandasの関数であるread_csvを使ってcsvファイルを読み込んでいる。
使い方:
pandas.read_csv(ファイル名,オプション)オプションの説明
encoding =: 文字コードの指定(ファイルの文字コードはコマンドラインで$nkf --guess (ファイル名)として調べられる。)header =:列のインデックス(e.g.,観測変数)がファイルの何行目にあるかを指定する(0から数え始めることに注意!)。index_col =:行インデックス(e.g.,日付)がファイルの何列目にあるかを指定する。parse_date =: インデックスを「日時」の型として読み込む場合にその列を指定する。リストとして指定(e.g.,[0])。- ..
※ 色々なオプションが付いていて複雑ですが、観測データの解析ではデータの読み込みに苦労することが多いです。上に示したプログラム例も、私がそれなりに試行錯誤した結果です(ので安心してください...?)。何もオプションをつけずに実行するとどうなるか、確認してみるとよいです。
◯ [関数] pandas.concat (データの結合)¶
使い方:
pandas.concat([ファイル1, ファイル2, ....], オプション)オプションの説明:
axis=: データを連結させる方向(0:行方向、1:列方向)。デフォルトは0join=:inner: 共通する部分があるものだけ抜き出す。outer:和集合をとる(一方のインデックスにしかデータが無い場合は、他方には>Nanが入る)key=: (列方向に連結する場合)行のインデックスを設定する。
これで(綺麗に)データを読み込むことができた。以下、必要に応じてデータを切り出して解析・描画する。まずはデータの切り出しについて、「1.2.1 インデックスで範囲指定する方法」と「1.2.2 条件指定する方法」の二つを学ぶ。
先にも説明したように、Pandasで扱うオブジェクトは各データにインデックスがタグ付けされている。これを活かして、インデックスで範囲指定して切り出すのが楽である。
まずはどんなインデックスがあるか調べよう。これは以下のようにすればよい:
df.indexdf.columns ※ 今回はデータを読み込む際にparse_dateのオプションを付けたので、行のインデックスはDatetimeIndexという、日付に関する処理を容易に行えるインデックス(型)になっている。
# どんなインデックスがあるのか参照してみる
## 行
print(dfm.index)
## 列
print(dfm.columns)
DatetimeIndex(['1960-01-01', '1960-01-02', '1960-01-03', '1960-01-04',
'1960-01-05', '1960-01-06', '1960-01-07', '1960-01-08',
'1960-01-09', '1960-01-10',
...
'2023-12-22', '2023-12-23', '2023-12-24', '2023-12-25',
'2023-12-26', '2023-12-27', '2023-12-28', '2023-12-29',
'2023-12-30', '2023-12-31'],
dtype='datetime64[ns]', name='年月日', length=23376, freq=None)
Index(['降水量の合計(mm)', '降水量の合計(mm).1', '降水量の合計(mm).2', '降水量の合計(mm).3', '平均気温(℃)',
'平均気温(℃).1', '平均気温(℃).2', '平均風速(m/s)', '平均風速(m/s).1', '平均風速(m/s).2',
'平均現地気圧(hPa)', '平均現地気圧(hPa).1', '平均現地気圧(hPa).2', '平均蒸気圧(hPa)',
'平均蒸気圧(hPa).1', '平均蒸気圧(hPa).2', '平均雲量(10分比)', '平均雲量(10分比).1',
'平均雲量(10分比).2', '最高気温(℃)', '最高気温(℃).1', '最高気温(℃).2', '最低気温(℃)',
'最低気温(℃).1', '最低気温(℃).2', '降雪量合計(cm)', '降雪量合計(cm).1', '降雪量合計(cm).2',
'降雪量合計(cm).3', '平均湿度(%)', '平均湿度(%).1', '平均湿度(%).2', '日照時間(時間)',
'日照時間(時間).1', '日照時間(時間).2', '日照時間(時間).3', '最多風向(16方位)', '最多風向(16方位).1',
'最多風向(16方位).2'],
dtype='object')
どんなインデックスがあるか分かったので、これらの範囲を指定してデータを切り出すことができる。
.loc[] (オススメ)¶列のインデックス(e.g.,変数)を指定: data['インデックス名'] or data.loc[:,'インデックス名']
行のインデックス(e.g.,時刻)を指定: data.loc['インデックス名']
時刻については、日付で範囲を指定することも可能: data.loc[最初の日付:最後の日付] 。datetime型で指定することも可能。
※ 列と行で指定方法が若干異なるので注意しましょう。
.iloc[]¶data.iloc[インデックス番号]
[start:end] とする(但し、endは含まれないことに注意)。# (1) "列" のインデックス指定
## '平均気温(℃)'を切り出す
temp = dfm['平均気温(℃)']
# (2) "行"のインデックス指定
## 'ある日付(e.g.,2021-01-10)のデータ'を切り出す
temp_1day = dfm.loc['2021-01-10','平均気温(℃)']
# datetime型で指定することも可能
#date_sub = dfm.loc[datetime.datetime(2017,1,10)]
時刻で範囲指定してみる
temp_sub = temp.loc['2021-01-10':'2021-01-12']
print(temp_sub)
年月日 2021-01-10 1.3 2021-01-11 2.6 2021-01-12 2.6 Name: 平均気温(℃), dtype: float64
特定の年月 のデータを切り出すことも可能である
##2017年1月のデータ(一か月間)を切り出してみる
temp_1month = temp.loc['2021-01']
print(temp_1month.head())
年月日 2021-01-01 2.1 2021-01-02 3.7 2021-01-03 4.7 2021-01-04 5.2 2021-01-05 5.1 Name: 平均気温(℃), dtype: float64
上ではある範囲のデータを丸ごと取り出したが、データ解析ではある条件を満たすデータのみを切り出したい場合がある。この時便利なのが真偽値配列(bool型)を用いた方法である。これは次のようにすれば良い:
これは実例を示すのが早いだろう。
# データ配列の例として
A = np.array([1, 2, 3, 4, 5])
# 1. 真偽値配列を作る
mask = np.array([True, False, True, False, False])
# 2. データ配列(A)から真偽値行列(mask)がTrueである要素のみを取り出す
print(A[mask])
[1 3]
#(1) 真偽値配列を作る
mask = temp_1month < 0
print("真偽値配列", mask.head())
#(2) Trueの要素だけ抜きだす
print(temp_1month[mask])
真偽値配列 年月日 2021-01-01 False 2021-01-02 False 2021-01-03 False 2021-01-04 False 2021-01-05 False Name: 平均気温(℃), dtype: bool 年月日 2021-01-08 -1.0 2021-01-09 -0.2 Name: 平均気温(℃), dtype: float64
最後に描画である。 pandasオブジェクトには、絵を描くメソッドが用意されている。まずはこれを使って簡単に図を描いてみよう(1.3.1節)。続いてmatplotlibを用いた一般的な描画方法を実習して体裁を整える方法を学ぶ(1.3.2節)。
※ 実際の(私の)研究では、データ解析の段階ではなるべくメソッドを用いて素早く沢山の図を描き(その分結果の吟味に時間をかける)、論文化の(人に見せる)段階で細部にこだわった図を描く、といったように両者を使い分けている。
pandasではデータにインデックスがタグ付けされているため、これらを軸情報としてお手軽に図を描くことができる。以下は代表例で、他にも色々とあるので興味があれば各自で調べてみてください。
ax = temp.plot() # たったこれだけで図が描ける!
ax.set_xlabel('Temperature') #軸のラベル(デフォルトで描くと文字化けするようなので設定)
# 図を表示する
plt.show()

ax = temp.plot.hist(bins=16,range=(-5,35)) #"bins"は、棒の本数(つまり、階級分けの細かさ)
ax.set_xlabel('Temp. (degrees C)') #ラベル(詳細は1.3.2参照;別にこの行はなくても動きます)
plt.show()

# ちょっと違った書き方を示す:予めグラフ領域を準備して、そこに図を埋め込む方式 (-->1.4節を参照のこと)
fig = plt.figure(figsize=(10,5))
ax1 = fig.add_subplot(111)
dfm.plot.scatter(ax=ax1,x='平均気温(℃)',y='平均現地気圧(hPa)') # 上で作ったax(図を描く領域)を"引数"として与える
ax1.set_xlabel('Temp.(degrees C)')
ax1.set_ylabel('Pressure (hPa)')
plt.show()

matplotlibは他の描画ライブラリのベースとなっていることが多く、数値配列全般について(Pandasの形式でなくても)プロットできるので、何かと応用が効く(実際、pandasの描画メソッドは内部においてmatplotlibを呼び出している)。
以下のプログラムではmatplotlib.pyplot関数をpltとして参照している。大まかな流れとしては、紙(1)と描画領域(2)を準備し、そこにグラフをプロットし(3)、必要であれば軸を追加したり体裁を整える(4)。
紙を用意: fig = plt.figure(figsize=(a,b))
figsize: 横-縦の比率(a:b)図を描く領域(サブプロット領域)を用意(複数作ることもできる): ax = fig.add_subplot(l,m,n)
(l,m,i): l(縦) x m(横) 個の領域を作って、そのうちi個目の領域サブプロット領域にグラフを描く:
ax.plot(x,y,color=,label=,linewidth=,linestyle=...) : ラインプロットax.bar(x,y,color=,label=,...) : 棒グラフax.scatter(x,y):散布図ax.hist(x,y,alpha=,...):ヒストグラム体裁を整える(軸、ラベル、タイトルなど): ax.set_xlabel() etc.
ax.set_xlabel('ラベル',fontsize=,color=), ax.set_ylabel('ラベル'): x軸, y軸のラベルax.set_xtitle('タイトル',fontsize=,color=,..),ax.set_ytitle('タイトル'): x軸, y軸のタイトルax.set_xlim([xmin,xmax]),ax.set_ylim([ymin,ymax]): x軸,y軸の範囲を設定ax.tick_params(axis=,direction=,colors=,labelsize=,...) :目盛りの書式を設定ax.legend(): 凡例を描く. plot関数で設定したlabelが書かれるax.set_title('タイトル'):サブプロットのタイトルfig.suptitle('タイトル'):フィギュアのタイトル図を保存する場合: plt.savefig(ファイル名)
図を画面表示!: plt.show()
注1)1, 2は以下のようにまとめてもよい:
fig, ax = plt.subplots(2, 2, figsize=(6, 4)): 最初にサブプロット領域を全部作ってしまう。ax[0,0].plot(x,y1):サブプロット領域に順々にアクセスして、それぞれに絵を描いていく。ax[1,0].plot(x,y2)注2)plotの引数には、リストや配列(ndarray型)だけでなく、pandasデータ(Series型)をそのまま渡すこともできる。
#ここでの例では、体裁を調整する方法を示すため、わざとオプションを多用しています(4)
#(本演習では細かい体裁までは求めませんので、ご参考まで)
# (1) 紙の用意(Figureオブジェクトの作成)
fig = plt.figure(figsize=(10,6))
# (2) 図を描く領域(サブプロット)を用意
ax = fig.add_subplot(211) # "2x1 = 2 個の領域を作って、そのうちの1つ目"という意味
ax2 = fig.add_subplot(212) # 2x1 領域の2つ目
# (3) 図を描く!
ax.bar(df.index,df['降水量の合計(mm)'],color='r',label='Precip.')
ax2.plot(df.index,df['平均気温(℃)'],color='b',linewidth=5,label='Temp.')
# (4) 体裁を整える
# タイトルと軸のラベル
ax.set_title('(a) Precipitation',fontsize=15)
ax.set_ylabel('Precipitation (mm)',fontsize=12)
ax2.set_title('(b) Temperature',fontsize=15)
ax2.set_ylabel('Temperature (m/s)',fontsize=12)
# 目盛りの書式の設定
ax.tick_params(axis="x",direction="out",colors="gray",labelcolor="gray") #x軸の設定
ax.tick_params(axis="y",direction="inout",colors="red",labelsize=11,width=3)
# 凡例を書く
ax.legend(loc=2) #loc: 凡例を書く場所を指定(0:適宜, 1:右上, 2:左上, ...)
ax2.legend(loc=2)
fig.suptitle('AMeDAS Kyoto',size=15)
# グラフを適当にずらして軸などが重ならないようにしてくれるオマジナイ
fig.tight_layout()
# このままではタイトルが重なるので上端にスペースを空ける
fig.subplots_adjust(top=0.9)
# (5) 図を保存
plt.savefig('Kyoto_pT_2017.png')
# (6) 画面表示
plt.show()

fig = plt.figure(figsize=(10,4))
ax = fig.add_subplot(111)
ax.bar(df.index,df['降水量の合計(mm)'],color='r',label='Precip.')
ax2 = ax.twinx() #x軸を共有する領域をもう一つ作る(右の軸を追加)
ax2.plot(df.index,df['平均気温(℃)'],color='b',label='Temp.')
ax.set_ylabel('Precipitation (mm/day)')
ax2.set_ylabel('Temperature (C)')
#凡例
ax.legend(loc=2)
ax2.legend(loc=1)
# 図を表示
plt.show()
